

I found the job through an online job board. I have a disability, so was looking for contracts for working from home, with flexible but full time hours. The job advertised was transcription, and as I was already transcribing in English on the gig market of Rev.com, at the time, I looked forward to being able to work on the same sorts of tasks, with the security of a job contract. A bonus for me was that I would be able to use my second language, and work with a diverse group that I imagined to include many other people knowing multiple languages. I applied for the job with the staffing agency based in Canada specializing in language-experts.
During the interview process, I was told that the main client for the staffing agency was going to be Google. Although I have a low opinion of Google as an employer, being aware that it accepts questionable contracts from the United States Department of Defense, busted unions, and mass-produced and monetized surveillance, I was also interested in learning more about how its products get built. Also, this contract seemed above board at the beginning, and the staffing agency would be issuing bi-weekly pay cheques, deducting taxes and Canadian pension plan amounts, as legally required.
During the initial testing and training period, we used our own home computers to complete the tasks. We would log into the Chrome browser window and open an Incognito tab, to access the Developer guidelines for our specific language. To qualify, I answered about 100 multiple choice and short audio listening and transcribing tasks, drafted by the staffing agency to test my grammar and spelling in the language that I was hired for my expertise.
Transcribing usually involves listening to some sound tape, and then rendering that sound into a typed, written record. This written log, or transcript, can be either a verbatim record, with every “um”, “ah” and false start in natural speech included and captured in the text, often useful in legal transcripts. Conversely, the transcript can be a less verbatim record, excluding those sorts of filler words, where what is most important is to capture the meaning of the words spoken, for example in a transcript of a journalistic interview or in academic research.
At Rev.com, I usually choose to work on non-verbatim transcripts. For Google, I was making a verbatim transcript of the language sounds, but not just verbatim. We were also capturing any other data in the sound, like noise, music and other features. Every different speaker was also labelled separately and specifically, as were any pre-recorded voices, like the operator voice in a voice mail system. The added complexity of the work made the work more interesting to me. The training period was paid.
I would meet the other workers via a Google Hangouts chat, including the dozen or so people who were working on my same specific language, in my case Spanish. There was a project manager in the group chat who was not fluent in Spanish, and was there mainly to answer questions about the technology.
We were told that our job was to fix the machine-produced text transcript of audio files, and that the data we generated during our work hours would go into training the company’s artificial intelligence, to improve its ability to capture human speech. In this way, we seemed to be training Google’s sound capture tools for how to actually replace us, the human workers.
The Work of Transcribing
To work, we would log in to a Google Doc spreadsheet, where my name appeared at the top of a column. In the cells under the column would automatically appear an alphanumeric string of characters. I would then copy and paste that string of characters into a separate Chrome browser tab at the end of a specific web address, which would then open the app where I was to work on each individual audio file.
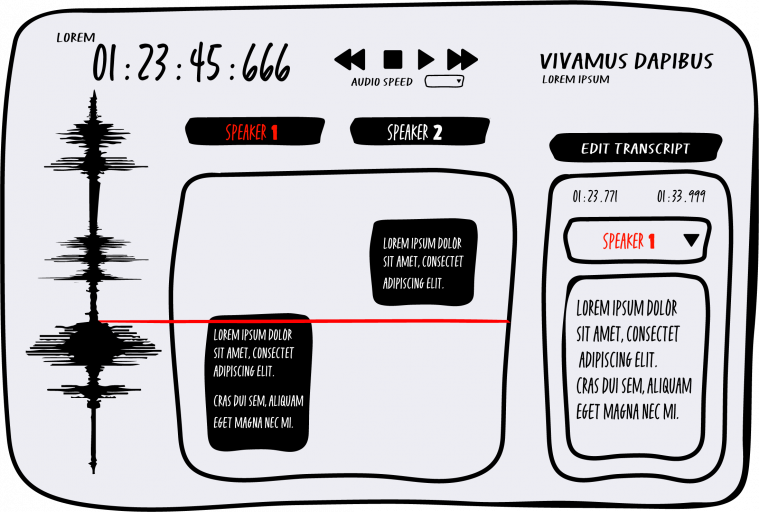
Once we did that, we’d get into the actual place where we were working. The transcribing tool looked like a lot of other sorts of web-based Google products, and it was called Loft. When you opened Loft, the screen was divided into three columns, with an upper menu-type view where the time codes told me how long the audio file was, and smaller time codes indicating where within that audio file the selection cursor was placed. The menu bar also had function buttons like Play, Pause, Fast Forward or Rewind, plus a string of random words (something like “aardvark antelope artifice”) that I guessed were a machine-generated name for the specific audio file. These words had nothing to do with the audio in the window, but they changed every time we would paste a new string of alphanumeric characters into the web browser address bar to open up a new audio file.
Below this menu bar, was the workspace. On the far left of the workspace there was a visual representation of the audio file you were working on, similar to how sound looks in audio editing software like Audacity or Pro Tools, with quiet audio looking like shorter lines and louder parts showing up as longer lines.
This visual of the sound waves was paired in the center of the screen with text boxes where the machine-generated and error-filled transcript would appear. On the far right of this screen appeared our options for correcting the machine transcript. In this far right column, floating text boxes allowed us to re-type the machine generated transcript, and to accurately change how the center column’s boxes would fit to the sound wave. Our job was to render every audio file perfectly in these options in the far right column of the screen. Before I started, I had to study a long and detailed document that was the Google style guide for my specific language. It defined stuff like how to capitalize, how many spaces to leave after a period, how to format the typing of different sorts of numbers when they were in the audio, etc.
For example, “if it is obvious from context that a number reflects an amount of currency, transcribe with the dollar sign $,” and stuff like that. For every type of sound, there was to be a very specific correct way to render it, either in text written into the transcript box, or in the noise labelling function of the app. How to render the transcript was extremely specific. If you were working on US English files, then workers had to spell it like “Okay”, whereas in Great British English (GB_En), the guidelines required the word to be spelled: “Ok”. In GB_En, if a speaker said a phrase that sounded like “wanna”, we had to write it exactly as it was spoken, as “wanna”. In a US_En file though, such a contraction wasn’t accepted, and we were expected to type out the full correct spelling, “want to”.
In order to render all the audio into textual data that the machine could read, there was a menu of options for labelling the sounds that were not words, and the text boxes that floated in the center column were to be adjusted so that the time code was exactly level with the sound wave, down to the millisecond. These floating boxes could overlap with each other, and each additional speaker needed to be identified with a number, which then became its own column (speaker 1, speaker 2, pre recorded speaker 1, etc).
Anything that was noise, personally identifiable information like a person’s name, or music had to be marked. These other sound markers showed-up in slightly different colours on the screen, separate from the text transcription. Again, this labelling had to be accurate down to the millisecond. There were keyboard short-cuts that would make the task of picking the exact timecode easier for each label, but at the start I was using just a regular laptop trackpad to select the place to mark the start and end of each audio utterance. Also, if you had to change your keyboard layout to some international layout, to type language specific characters, then the keyboard shortcuts would no longer work.
I did not have a keyboard that was optimised for the special characters unique to the Spanish language, but I was already used to switching my keyboard layouts in the International set-up menus of my operating system, to be able to type special characters like á or ñ. I was told once I passed training, the company would provide equipment optimised to my language. Eventually the promised work computer did arrive, but disappointingly, it did not include a Spanish keyboard. It was just a higher end Chromebook. An external keyboard with those specific Spanish characters was promised, but never sent. All other equipment that I needed to make my workspace ergonomic, like good headphones to hear the audio better, an external mouse to avoid use of the built-in laptop trackpad, and a laptop stand to tilt the Chomebook’s keyboard to a better angle for typing, was equipment I supplied myself. Having the work machine did at least make it possible to keep work hours and personal computing hours separate, though.
For the first period of my work, I was being paid a few cents over what was minimum wage for my jurisdiction. We were paid by the hour worked, and were told we had to meet certain targets for how much audio we processed through Loft in that time. I never had any problem with meeting these targets, and benefited from being able to adapt to my disability needs.
However, this changed when the staffing company laid me off a few months into the work, stating that Google had stopped sending them work. I later found out when they filed my record of employment with the Government of Canada, that the staffing agency told the Government that they laid me off during the probationary period. This was not the case, as my work contract had specified a probation period of three months and I worked at least six. They also laid me off before I passed the threshold of the required amount of hours to qualify for unemployment insurance. Other workers might have had a different experience, and been able to file for government unemployment benefits after this contract ended, but I was not.
Working as an independent contractor
A few weeks after I was legally laid-off, the staffing agency got back in touch and offered me to return to the same work. They were not offering to hire me back as a full time worker, anymore, with pension and vacation hour deductions. Instead, we would be contracted as independent freelancers, and had to register via a further intermediary, either Upwork.com or Guru.com. This intermediary would take a large percentage off of each pay cheque, Upwork taking between 10% and 20% of the total pay, and Guru taking around 9% (we were not informed about the differences between these platforms by the staffing agency and I had to do my own research, only later finding out that I had selected the most exploitive intermediary of the two options).
This time, there were about 100 people in the Google Hangouts chat group where all the people in my language group were to meet for work. I didn’t recognize anyone from the first period, it was all new workers, and most people only beginning to be trained in the software. It became really difficult to use the chatroom for useful training, as people began to use it for asking routine questions that I already knew the answers to, or to ask for a reviewer to look at their files so they could get paid for them. We were no longer being paid by the hour worked, either, so this training effort was unpaid. This time, we were paid by piece-work, according to how much audio we managed to transcribe.
As an independent contractor, there was also a difference in the types of audio files that we were tasked with rendering into text and noise labels. In the first period of work, we were working with cleaner audio that Google had seemingly bought from call centres. This sort of sound file had only one or two speakers, and minimal noise and music. In the second period, as independents, we were working on transcribing audio that had been scraped from YouTube uploads, so there were multiple speakers, sometimes up to a dozen, and a lot of music and noise that we needed to label. We were told that if we were having trouble identifying what was said in the audio, we should look for the specific YouTube video the audio came from, but the information of which YouTube video the audio came from was not supplied by the company. Instead, we’d have to listen to the file, try to discern some keywords like the name of the topics or the YouTuber, then search those keywords in YouTube to try to find the right video. We also had already returned the company Chromebooks, and so were fully working on our own home computers and systems.
It also became clear the staffing company was not reflecting in the Upwork contract the true nature of my work. They had hired me for a nominal $5 contract on Upwork, and then paid the actual wages to me as “expenses reimbursement.” This, I think, was so that one couldn’t build one’s profile on Upwork and bid for work from other companies that might offer better pay. I was still expected to log into the Google Docs spreadsheet and keep the record there of the files that I worked on, but none of this incidental time spent on keeping the record of what tasks I worked, was reflected in the pay. Instead, they were only paying by the audio minute successfully transcribed. Even for me, as someone trained and proficient in the Loft tool, it could take 30 or 40 minutes to correctly label and transcribe all the words and noise in a three minute audio clip. So, the pay had dropped far, far below legal standards.
For some of the newer people joining the group chat, a 30 minute piece of audio could take up to a week or more to clean up and correctly label every single audio feature and utterance. The pay for the work when I was first hired by the staffing agency was $12 per hour for 60 hours a week, so $720 per week. When I was hired through Upwork, the rate of pay was to be $4 per audio minute transcribed. The highest I was able to earn in a week was $90, as we were now competing with so many more workers for the quantity of tasks available. Because of this low rate of pay, there was a high turnover in people quitting and leaving the chat. I also noticed that most of the workers who were in the Google Hangout for the Spanish transcriptions were no longer located in Canada, and were instead in countries like Venezuela and Bolivia, where a $USD pay cheque could go farther when converted to local currency. The project manager was a freelancer hired in Turkey, and the reviewers were in Argentina, Ireland, or other places.
There also began to be a big delay between when a piece of work was finished by a worker, and when it could get reviewed by a reviewer. Because we were only paid for audio that had passed muster and been approved by a reviewer, people complained about this delay in approvals. If your transcripts didn’t get reviewed quickly, it could mean no pay or low pay in a given week, depending on how backed up the reviewers were and how messy the transcripts they were seeing were. We were not paid for any of the time spent getting training in the Google Hangout chat, or the time we’d work fixing our transcripts that did not pass an initial review.
I think that the staffing company laid-off its local workforce in order to rely on contract workers, because it wanted to evade legal liabilities like paying national pension plan amounts and vacation hours. According to an article praising the company on Upwork (archived version), the staffing agency was “lean” and could hire transcribers for 70 different language groups, despite having a management staff of only one person as far as I could tell. The accounting and human resources functions were also being contracted out to different people hired through Upwork, or maybe even done by the same person, just responding from different email addresses. According to the article on Upwork, LinguistixTank’s “volume ranges from 100 to 3,000 freelancers at one time” while Google was sending projects that “can last a few days to a few months.” This article says that the company’s “go-to resource” was “90% freelance talent”, and the staffing company “contracted experts in HR, business coaching, and marketing”, all through these so-called freelance or gig markets.
After the pandemic
Google stopped sending transcribing tasks to us freelancers in June of 2020, blaming the global pandemic. They notified workers that the contract might resume in October, but this never happened.
The only place to interact with co-workers being a Google Hangouts chatroom surveilled by the company, it was very difficult to talk to co-workers about our working conditions and to find a way to form common demands. It is also hard to contact other Upwork users and fight against this practice of under-the-table $5 contracts with wages paid out as expenses. The only feedback mechanism against the staffing company would be to leave a 1 star review on Upwork, which they’d likely respond to by doing the same against your freelance profile, and prevent you from bidding for other gigs.
If other freelancers have very distinctive first and last names, it is possible to search for them on other platforms like Facebook, or LinkedIn, and contact them there to try to build rapport and trust, but as most people are language experts in non-English languages, to think about suing for damages the most profitable company on the planet in their home jurisdiction of California, where it is a massive employer with deep pockets for lobbying, is a daunting proposal.
At this point you may be wondering, can I join a union, namely the new Google-specific Alphabet Workers Union? Well, no. “If you’re not currently doing work for Alphabet, or currently contesting your termination, AWU isn’t the right fit,” one union organizer told me.
Because Google laid us all off in June and we never had the chance to even speak to the company directly about our work let alone our terminations, contesting our termination collectively doesn’t seem to be an option. So, is Google, the staffing agency, or Upwork the most responsible for our poor labour conditions? Is there a way to jointly merge the responsibilities of these companies, to combat how they diffuse their responsibilities to workers when they distribute contracting in this way?
In the end, we may have successfully trained the artificial intelligence systems at Google on how to replace us humans, for now. Every time you are able to switch on automatic Closed Captions for a YouTube video, or during a Google Meet conference call, to seamlessly render into text the audio of what is being said in real time, using so-called artificial intelligence, I hope you remember the people who worked for far below a living wage, to make that technology possible.
This text is a contribution to the Berliner Gazette’s SILENT WORKS text series; its German translation is available on Berliner Gazette: https://berlinergazette.de/google-ki-prekaere-arbeit/ You can find SILENT WORKS video talks, artworks, booklets, workshop projects, and audio documents tackling AI-capitalism’s hidden labor on the English-language SILENT WORKS website. Have a look here: https://silentworks.info